

Working Both Sides of the Gap
What Building, Training, and Researching AI Taught Me About the Space Between Intent and Experience
A three-part study in AI from the inside out — as a builder, a model trainer, and a researcher of how real users adopt AI tools.

My research practice is built around one core question: what happens in the gap between how something is designed and how people actually experience it?
For most of my career, I study that gap from the outside — observing users, interviewing them, synthesizing what I find into recommendations for teams who are building things. But over the past two years, I've been inside the gap in a different way. I've built an AI product. I've trained AI models. And I've spent months in longitudinal research watching teachers — some of the most skeptical and time-pressured users of any technology — slowly, specifically, and sometimes surprisingly start to trust AI tools.
This case study is the story of what those three experiences taught me, and why I think they belong together.
Part One
Building BrickBreaker
What I learned about AI by being the user who didn't know what she didn't know.
The Problem
I've been researching my family genealogy for years, and I’ve hit what is commonly referred to as a brick wall in genealogy research.
This happens when you’ve reached the end of what your ancestor’s papertrail can tell you. There are many reasons this can happen, like missing or destroyed records, a lack of access to archives, or an undocumented surname change.
In 2026, the end of the paper trail is no longer an unbreakable wall, thanks to genetic genealogy.
Products like AncestryDNA or MyHeritage take the results of your DNA test and generate thousands of DNA matches and cluster groupings of individuals with shared DNA.
This is exciting, but it’s also created an entirely new problem area. Having an overwhelming amount of genetic data with no context, no existing family tree, nothing that can be used to even start formulating a testable hypothesis.
The analysis required to develop a hypothesis — how might you be related to your new cluster of shared matches? What surnames keep appearing? If you don’t know any of this, sorting through the data is painstaking, manual, and easy to get wrong.
I wanted to explore Claude Code, and I had been trying to manually come up with a solution for sorting through DNA shared matches.
I am a curious person, and also a creative. I decided to explore the actual capabilities of Claude Code for someone like me, a creative with some working knowledge of product design. It put me in the driver’s seat, and allowed me to self reflect first hand, user testing.
My curiosity and my very real desire to solve my own particular puzzle, drove me to develop BrickBreaker through Claude Code.
BrickBreaker was designed to let users upload their DNA match CSVs and cluster data from AncestryDNA and MyHeritage, and use AI and algorithmic analysis to surface the most likely shared surnames and match relationships — generating testable hypotheses for breaking down exactly this kind of brick wall.
Note: This isn't a prototype or a demo. BrickBreaker is a working tool I built to solve my own research problem and that is actively used to investigate my own real brick wall ancestor: Ellie Bisson, born 1904 in Quebec, Canada.

What I Expected
I came into this project feeling genuinely tech-savvy. I'd been using AI tools in my research practice for years. I understood how to prompt, how to iterate, how to work with AI-generated output critically. I assumed building with Claude Code would feel like a natural extension of that.
It did not.
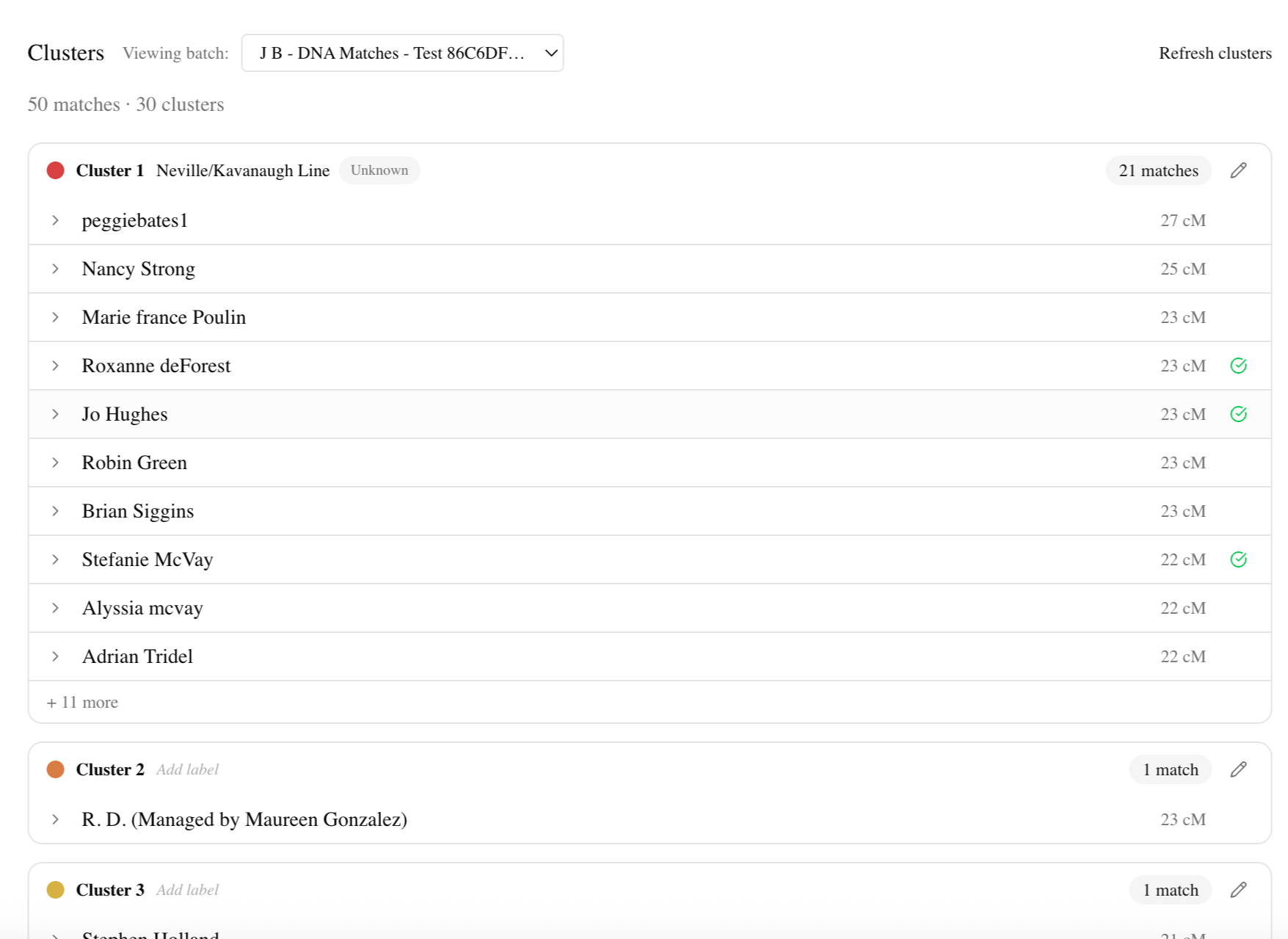
DNA Match Clustering: 50 matches grouped into 30 family line clusters, with the Neville/Kavanaugh line surfacing as the strongest signal.
What I Learned
Building BrickBreaker was one of the most instructive experiences of my professional life — not because it went smoothly, but because of where and how it didn't.
The ambition of what I wanted to build was significantly larger than I'd estimated. What seemed like a focused, well-scoped tool turned out to have layers of complexity I hadn't accounted for: data parsing logic, clustering algorithm integration, hypothesis generation that was meaningful rather than just pattern-matched. Each layer revealed another layer underneath.
More importantly, I learned something about what it actually means to build with AI tools that I couldn't have learned any other way. Working with Claude Code requires a specific kind of thinking that I'd describe as methodical invention — you need to know exactly what you want to build, be able to break it into the smallest possible discrete steps, and hold the full picture in your head while executing one piece at a time. It is not a tool that rewards vague ambition or fuzzy scoping. It rewards precision, patience, and the willingness to strip your expectations down to what's actually achievable in a single iteration.
I also encountered, firsthand, the assumptions I hadn't known I was carrying. I assumed that because I could describe what I wanted clearly, the tool would understand it the way I meant it. I assumed my instinct for what was "a small step" was calibrated to how the tool actually worked. Neither assumption held. The experience gave me a researcher's understanding of the specific places where AI tools and users misalign — not from observation, but from being the user who misaligned.
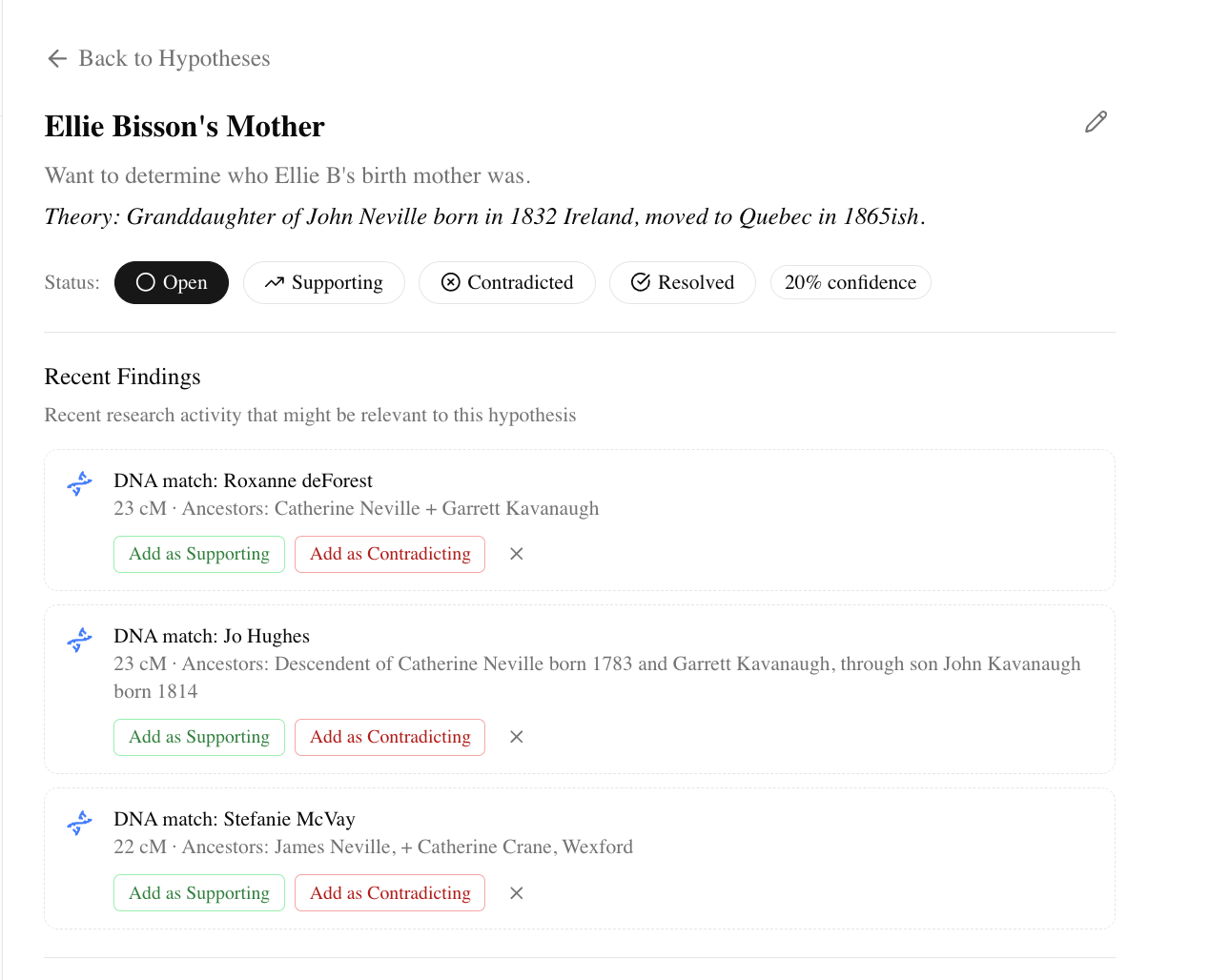
Why This Matters for Research
The most valuable thing I took from building BrickBreaker wasn't the tool itself. It was a new mental model for how AI products create friction — one that's grounded in firsthand experience rather than observed behavior. When I research how users interact with AI tools now, I bring a builder's understanding of where the seams are, where the tool's logic diverges from user expectation, and why even confident, capable users hit walls they didn't see coming.
I also came away with a specific, hard-won perspective on AI product design: the gap between what an AI tool can do and what users think it can do is almost always larger than the team that built it realizes. That gap is where I do my best work.
Training Models at DataAnnotation
Part Two
What labeling data taught me about how models fail
The Work
As part of my effort to understand AI from the inside, I spent time doing data annotation work — evaluating and labeling AI-generated content across a range of task types: multi-turn conversations with different user intents (brainstorming, roleplay, research queries), image evaluation, shopping intent classification, and research response quality assessment.
The work was systematic and repetitive by design. That repetition turned out to be instructive.
What I Noticed
Across hundreds of model outputs, certain failure patterns appeared with enough consistency to be meaningful:
Repetition at the structural level.
Many models struggle to vary their output structure across a conversation. The same opening moves, the same transitional phrases, the same concluding gestures — users don't always consciously notice this, but it creates a subtle sense of interacting with something mechanical rather than something responsive.
Verbose, hedge-heavy openings.
Model outputs frequently began with preamble that restated the question, acknowledged its complexity, or flagged caveats before delivering any substance. For users who are task-oriented — which most users most of the time are — this reads as friction, not care.
Tone calibration failures.
The gap between what a user's message signals about their emotional state or intent and what the model's response reflects was a recurring issue. A casual question getting a formal answer. A distressed message getting a cheerful one. These mismatches are subtle but they erode trust.
Visual scannability as an afterthought.
Many outputs were difficult to scan — long paragraphs where headers or bullets would have served the user better, or over-formatted responses where plain prose would have felt more human. The model's logic for when to format and when not to felt inconsistent and often misaligned with what the user actually needed.

Users can tell you they found an AI response unsatisfying. They're less able to tell you exactly why. Annotation work gave me the pattern-level language to bridge that gap.
Why This Matters for Research
Annotation work gave me a granular, pattern-level understanding of AI failure modes that's difficult to develop from user research alone.
Taking this experience on was so valuable to me because it put me in the role of a first hand AI user, and allowed me to compare and contrast responses, have first hand feelings of being impressed, confused, or disappointed. I learned how to put these issues into actionable feedback.
Users can tell you they found an AI response unsatisfying; they're less able to tell you exactly why. Having spent time on the output side — evaluating what made responses work and what made them fall short — I can now move between the user's experience and the model's behavior in ways that make my research more precise and more useful to the teams acting on it.
Part Three
Researching How Teachers Adopted AI
What longitudinal trust research taught me about the gap between anxiety and adoption
The Context
Over the past year and a half, I've been doing ongoing research into teacher and parent sentiment around AI — both at the consumer level (individual parents and teachers making personal choices about AI tools) and at the enterprise level (schools and organizations making platform and policy decisions). The research has been longitudinal by necessity: AI adoption in education is not a static phenomenon, and the story has changed meaningfully over the period I've been studying it.
What I Found
When I started this research, teacher sentiment around AI was predominantly cautious — a mix of skepticism, concern about academic integrity, and uncertainty about where AI fit into a profession built around human relationship and judgment. Many teachers I spoke with were waiting to be told what to do by their institutions, or quietly avoiding AI tools altogether.
A year later, that picture looks different. Not uniformly — there's still a wide range of attitudes — but the direction of travel is clear. Teachers are more willing to experiment. More importantly, they've started to find specific, personal use cases that make the value of AI concrete rather than abstract.
The moments that stand out from my interviews:
A middle school teacher described using AI to create a customized assignment for a student with autism who was obsessed with soccer. The assignment covered the required curriculum content but was built entirely around soccer statistics, soccer history, and soccer strategy. He told me he would never have had the time to create something that specific and that tailored without AI — and that the student's engagement was unlike anything he'd seen from him before. For this teacher, AI stopped being an abstraction the moment it helped him do something he'd always wanted to do but couldn't.
A high school history teacher described creating a George Washington chatbot as a classroom tool — a way for students to "interview" Washington about his decisions, his era, his contradictions. She used it as a reward for students who finished their work, and described the engagement it generated as something she simply couldn't have created three years ago. For her, AI unlocked a kind of personalized, interactive learning experience that had previously existed only in well-funded, well-resourced classrooms.
The Finding That Matters
The pattern across these interviews pointed to something that I think has significant implications for AI product design in education: adoption isn't driven by features — it's driven by moments of personal relevance. Teachers don't adopt AI tools because they're powerful or comprehensive or strategically important. They adopt them the moment AI helps them do something specific that they couldn't do before — something that matters to them, for a specific student, in a specific situation.
This finding sits in direct tension with how most B2B EdTech companies are approaching AI right now. In my observation, the dominant posture among product teams is anxiety-driven: a fear of missing the AI moment, a rush to integrate AI features without a clear theory of how those features map to actual teacher workflows. The result is products that have AI capabilities without AI value — tools that can technically do things teachers don't actually need, while missing the specific moments of personal relevance that would drive real adoption.
The gap I keep finding isn't between what AI can do and what products implement. It's between what products implement and what users actually need from AI in the specific, human, situational moments of their working lives.
That's the gap I research.
What These Three Experiences Add Up To
I've spent the past two years engaging with AI from three different vantage points — as a builder hitting the limits of my own assumptions, as a trainer developing a pattern-level understanding of model failure, and as a researcher watching real users find their way to trust through specific, personal moments of value.
What I've come away with is a research practice that understands AI not as a category to study from the outside, but as a set of systems, assumptions, and human relationships that I've engaged with from the inside. I know where the gaps are because I've been in them.
That's what I bring to AI product research. Not just a methodology. A vantage point.
Skills and Methods Used
Longitudinal qualitative research · Stakeholder interviews · User interviews · AI-assisted synthesis (Claude Code, Dovetail AI) · Model output evaluation and annotation · Prototype development · Pattern analysis · Research ops
A Note on This Case Study
Unlike my client work — which is password protected out of respect for confidentiality — this case study draws on my own independent research, annotation work, and product development. It is fully open.
If you'd like to discuss any of this work in more detail, I'd welcome the conversation.